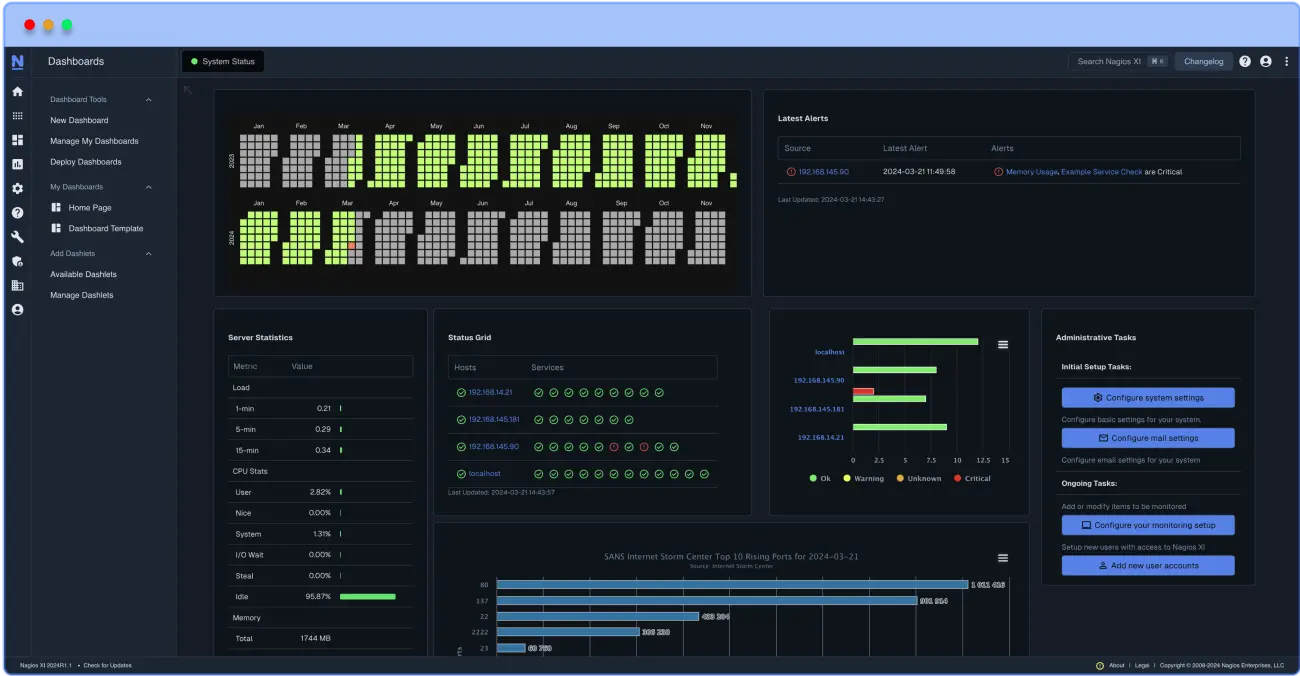
Server monitoring is the process of continuously tracking and observing the performance, availability, and functionality of a server to ensure it operates as expected. This includes checking key metrics like CPU usage, memory consumption, disk usage, network activity, and the health of specific applications or services running on the server.
Nagios is recognized as the top solution to monitor servers in a variety of different ways. Server monitoring is made easy in Nagios because of the flexibility to monitor your servers with and without agents. With over 3500 different add-ons available to monitor your servers, the community at the Nagios Exchange has left no stone unturned.
Nagios is fully capable of monitoring Windows servers, Linux servers, Unix servers, Solaris, AIX, HP-UX, Mac OS X, and more.
Implementing effective server monitoring with Nagios offers the following benefits:
With its proactive approach and extensive capabilities, Nagios ensures a reliable and efficient IT infrastructure.
Nagios is an excellent choice for server monitoring because it offers comprehensive visibility into server health, performance, and resource utilization. It rapidly detects server outages, protocol failures, and application errors, enabling teams to respond quickly and minimize downtime. With customizable alerts sent via email, SMS, or integrations like Slack, Nagios ensures timely notification of critical issues. Its scalability makes it suitable for networks of any size, from small setups to large enterprise environments. Nagios centralizes management through a user-friendly dashboard and supports detailed reporting and historical logs, helping teams track performance trends and plan for future growth. Additionally, its extensive plugin ecosystem and compatibility with diverse platforms like Windows, Linux, and UNIX allow tailored monitoring for a wide variety of systems. By proactively identifying and addressing issues, Nagios enhances server reliability, optimizes resource usage, and supports smooth IT operations, all while remaining cost-effective.
Nagios monitor servers by performing regular checks, sending alerts, and providing detailed insights into server health and performance, as outlined below:
Reduce downtime and boost efficiency with proactive monitoring to ensure your systems run smoothly.